app library
the grid
hundreds of tools that run serverless on CPU or GPU.
call directly via API or let agents orchestrate them.
featured

p-video-avatar
Generate talking head videos from a portrait image with text or audio-driven speech

veo-3-1-fast
Veo 3.1 Fast via Vertex AI - Generate videos from text prompts or images with optional audio

flux-1-kontext-dev
Edits existing images using text instructions, allowing for changes in style, characters, or objects, and reliably handles multiple edits while maintaining image coherence.

bytedance-uso
A unified image editor that allows users to generate images by combining any subject with any style efficiently, preserving identity and consistency.
all apps

pruna/p-video-avatar
generate talking head videos from a portrait image with text or audio-driven speech
fastly/domain-search
domain research api — search for available domains and check registration status

infsh/harrier-oss-v1
multilingual text embedding using microsoft's harrier oss v1 models. supports retrieval, clustering, semantic similarity, classification, and reranking with state-of-the-art mteb v2 scores.

ceramic/search
web search powered by ceramic ai

bytedance/seedance-2-0-mini
cost-effective multimodal video generation from text, images, video, and audio references using bytedance's seedance 2.0 mini model via byteplus ark api. ~50% cheaper than seedance 2.0, supports text-to-video, image-to-video, and multimodal reference-to-video with synchronized audio.

bytedance/seedream-5-pro
bytedance's flagship seedream 5.0 pro image model via byteplus ark api. precision creation and editing with pixel-level regional edits, intelligent layer understanding, complex infographic generation, multi-reference blending (up to 10 images), and native text rendering in 14 languages.

topaz/video-upscale
video upscaling and enhancement — proteus family models for precision upscaling, deinterlacing, face recovery, and cgi enhancement
arxiv/search
search arxiv papers by query with field prefixes, boolean operators, category filtering, and sorting
biorxiv/search
search biorxiv and medrxiv preprints by date range with optional category filtering

chemrxiv/search
search chemrxiv preprints via crossref api

arxiv/paper
get a specific arxiv paper by its id with full metadata including title, authors, abstract, and links

chemrxiv/paper
get a chemrxiv paper by doi via crossref api

biorxiv/paper
get a specific biorxiv or medrxiv paper by its doi

topaz/astra
creative video upscaling — ai-guided upscaling with prompt and creativity controls

topaz/starlight
generative video upscaling — precision, hq, mini, sharp, and fast models

topaz/denoise
video denoising — nyx family models for noise, compression, and artifact removal

topaz/video-utilities
video utilities — motion deblur, colorization, and sdr to hdr conversion

topaz/frame-interpolation
video frame interpolation — slowmo and fps boost with apollo, chronos, and aion models

topaz/proteus
proteus video upscaling and enhancement — precision upscaling, deinterlacing, face recovery, and cgi enhancement

you/contents
contents api — fetch clean markdown or html from any url, batch up to 10 pages per request

you/finance-research
finance research api — agentic financial research with filings, macro data, and institutional-grade sources

you/research
deep research api — multi-step web research with source-backed citations and configurable effort levels

you/search
web search api — ground your apps in reliable, web-scale knowledge with contextual snippets

anthropic/claude-sonnet-5
claude sonnet 5 — frontier sonnet with near-opus performance. 1m context, vision, extended thinking, tool use. direct api.
anthropic/claude-opus-4-8
claude opus 4.8 — anthropic's most capable opus model. 1m context, 128k output, vision, extended thinking, tool use. direct api.

google/gemini-3-1-flash-lite-image
gemini 3.1 flash lite image (nanobanana 2 lite) via vertex ai — ultra-low latency image generation

google/gemini-omni-flash
gemini omni flash — text-to-video with synchronized audio, grounded in real-world knowledge

microsoft/mai-image-2-5
mai image 2.5 — microsoft's photorealistic image generation and editing model with fine-grained pixel-level control.

openrouter/glm-5-2
glm 5.2 - zhipu's latest flagship language model with 1m context via openrouter

reve/remix
reve remix — create images from text and 1-6 reference images combined.

reve/edit
reve edit — edit images with natural language instructions. top 3 on lmarena leaderboard.

reve/create
reve create — generate images from text with best-in-class prompt adherence and text rendering.

pruna/p-video-replace
replace characters in videos using reference images. preserves motion, timing, camera, and scene.

anthropic/claude-mythos-5
claude mythos 5 — project glasswing. successor to claude mythos preview. 1m context, 128k output, adaptive thinking, vision, tool use. direct api.

anthropic/claude-fable-5
claude fable 5 — anthropic's most capable widely released model. 1m context, 128k output, adaptive thinking, vision, tool use. direct api.
elevenlabs/voice-remix
elevenlabs voice remix - modify voice characteristics like accent, gender, style, pacing
elevenlabs/voice-clone
elevenlabs voice clone - instantly clone a voice from audio samples

elevenlabs/voice-design
elevenlabs voice design - create custom ai voices from text descriptions

x/post-search
search recent posts on x.com. use conversation_id to get replies to a tweet, or any x search query. returns up to 100 posts with text, author, and engagement metrics.

google/gemini-3-pro-image
gemini 3 pro image (nanobanana pro) via vertex ai - advanced image generation model powered by google cloud

google/gemini-3-1-flash-image
gemini 3.1 flash image (nanobanana 2) via vertex ai - advanced image generation model powered by google cloud

infsh/deepseek-ocr-2
next-gen document ocr with improved math, tables, and reading order. converts images and pdfs to structured markdown.

heygen/create-avatar
create heygen avatars from video footage (digital twin), a photo (photo avatar), or a text prompt (ai-generated). returns a look id for use with avatar-video.

openrouter/qwen3-32b
qwen3 32b - powerful dense language model with reasoning and tool use capabilities via openrouter

openrouter/qwen3-8b
qwen3 8b - efficient dense language model with reasoning and tool use capabilities via openrouter

anthropic/claude-haiku-45
claude haiku 4.5 — fastest and most affordable claude. 200k context, 64k output, vision, extended thinking, tool use. direct api.

anthropic/claude-sonnet-45
claude sonnet 4.5 — previous generation sonnet. 200k context, 64k output, vision, extended thinking, tool use. direct api.

anthropic/claude-sonnet-46
claude sonnet 4.6 — best balance of speed and intelligence. 1m context, 64k output, vision, extended thinking, tool use. direct api.

anthropic/claude-opus-46
claude opus 4.6 — previous generation opus. 1m context, 128k output, vision, extended thinking, tool use. direct api.

anthropic/claude-opus-47
claude opus 4.7 — anthropic's most capable model. 1m context, 128k output, vision, extended thinking, tool use. direct api.

heygen/text-to-speech
generate natural speech audio from text using heygen's starfish tts engine. supports configurable voice, speed, ssml input, and multiple languages.

heygen/lipsync
re-sync video lip movements to new audio using heygen's lipsync technology. supports speed and precision modes with optional captioning.

heygen/video-translate
translate videos into 30+ languages with voice cloning and lip-sync using heygen. supports speed and precision modes with optional captioning.

heygen/video-agent
generate complete videos from natural language prompts using heygen's ai video agent. the agent handles avatar selection, scripting, and production automatically.

heygen/photo-video
animate portrait photos into talking videos using heygen. upload a face image and add speech with configurable voice, motion prompts, and expressiveness.

heygen/avatar-video
generate talking avatar videos using heygen's digital and photo avatars with avatar iv or v engines, configurable voice, resolution up to 4k, and expressiveness.

veed/subtitles
add professional burned-in subtitles to videos with 25+ style presets. supports 100+ languages with automatic transcription or custom srt files.

infsh/html-to-video
render html/css/js animations to video — supports gsap timelines, css animations, web animations api

klingai/image-v2
kling image v2 (kolors v2.0) - text-to-image with 2k resolution, multi-image reference, and restyle. restyle output matches input resolution.

klingai/image-o1
kling image o1 (kolors image-o1) - omni image generation with element control. text-to-image and image-to-image at 1k/2k. $0.028/image.

klingai/image-3o
kling image 3o (kolors image-3o) - most capable image model with native 4k, series-image generation, and element control. $0.028/image (4k $0.056).

klingai/image-v1
kling image v1 (kolors v1.0) - basic text-to-image and image-to-image generation. cheapest option at $0.0035/image.

klingai/image-v1-5
kling image v1.5 (kolors v1.5) - text-to-image with subject and face reference for character consistency. generate images preserving a person's appearance.

klingai/image-v2-1
kling image v2.1 (kolors v2.1) - text-to-image and multi-image reference generation. combine multiple images for complex compositions.

klingai/image-v3
kling image v3 (kolors v3.0) - latest image generation model with 1k/2k resolution support. highest quality text-to-image.

klingai/video-v3
kling v3.0 - latest and most capable video generation model. native 4k output, multi-shot generation, flexible 3-15s duration billed per second, element control, motion control, and synchronized audio.

klingai/video-v2-6
kling v2.6 video generation with native sound and voice control. supports text-to-video and image-to-video with start/end frames, synchronized audio generation, and voice-driven character animation.

klingai/video-o1
kling video o1 (omni) - unified video generation with text, image references, start/end frames, element references, and video references for editing and style transfer. the most capable kling model.

klingai/video-v2-5
kling v2.5 turbo - fast video generation from text and images. supports start/end frame interpolation in pro mode. optimized for speed while maintaining high quality at up to 1080p.

klingai/lip-sync
kling lip sync - drive mouth movements in videos using text or audio. ideal for dubbing, adding speech to silent videos, or replacing dialogue.

klingai/avatar
kling avatar - generate digital human broadcast-style talking head videos from a single face photo. provide text or audio for the avatar to speak.

klingai/video-to-audio
kling video-to-audio - add generated sound effects, ambient audio, or music to any video. works with kling-generated and user-uploaded videos (3-20s).

klingai/virtual-tryon
kling virtual try-on - ai clothing try-on from a person photo and clothing image. supports single items and upper+lower combos (v1.5). $0.07 per generation.

inworld/voice-cloning
clone a voice from 5-15 seconds of audio using inworld instant voice cloning. use the cloned voice id with any inworld tts model.

inworld/voice-design
design a custom voice from a text description using inworld ai. describe the voice you want and get up to 3 previews. publish the one you like to use with any inworld tts model.

inworld/text-to-speech-2
inworld tts-2 - high-quality multilingual text-to-speech with 100+ languages and natural-language steering
inworld/text-to-speech-1-5-max
inworld tts 1.5 max - low-latency text-to-speech with 15 languages (<200ms p50)

inworld/speech-to-text
inworld speech to text - multi-provider speech transcription with word timestamps

inworld/text-to-speech-1-5-mini
inworld tts 1.5 mini - ultra-low-latency text-to-speech with 15 languages (~120ms p50)

openrouter/claude-sonnet-46
sonnet 4.

openrouter/hy3-preview
hy3 preview is a high-efficiency mixture-of-experts model from tencent designed for agentic workflows and production use.

openrouter/gemini-3-flash-preview
gemini 3 flash preview is a high speed, high value thinking model designed for agentic workflows, multi turn chat, and coding assistance.

openrouter/kimi-k26
kimi k2.

openrouter/claude-opus-47
opus 4.

xai/grok-imagine-image-quality
generate and edit high-quality images using xai's grok imagine quality model. supports 1k and 2k output resolutions with text-to-image and image editing.

infsh/hyperframes-render
render heygen hyperframes compositions to video — supports clips, gsap timelines, track layering

bria/rmbg
remove the background from an image, producing a transparent cutout. the general-purpose background removal — for product-specific cutouts, use product-cutout instead. output can be passed to replace-background, blur-background, or any editing app.

bria/increase-resolution
upscale images 2x or 4x (max 8192x8192) while preserving original content

bria/expand
expand image canvas with ai-generated content matching the original scene

bria/erase
remove objects from images using mask-based inpainting while preserving quality

bria/generate
generate images from text prompts using bria fibo

bria/generate-lite
fast image generation from text prompts using bria fibo lite

bria/structured-prompt
generate structured prompt json from text or images using bria

bria/ads-generate
generate multiple ads in various sizes from templates and brand assets

bria/product-cutout
cut out product from image with transparent background

bria/gen-fill
generative fill — replace masked regions with ai-generated content guided by a text prompt

bria/product-packshot
generate professional 2000x2000 product packshot images

bria/replace-background
replace image background with ai-generated content from a text prompt or reference image

bria/video-rmbg
remove background from videos with optional color replacement

bria/product-shadow
add realistic shadows to product cutout images
not enough? create new apps fast. templates + coding agents make it insanely extensible.
create your own apps
start from templates. add code, packages, docs. deploy in minutes.
schemas become tool parameters automatically. your app shows up in the grid and can be used by agents and workflows.
create workflows
build a graph of apps. deploy as a single callable app.
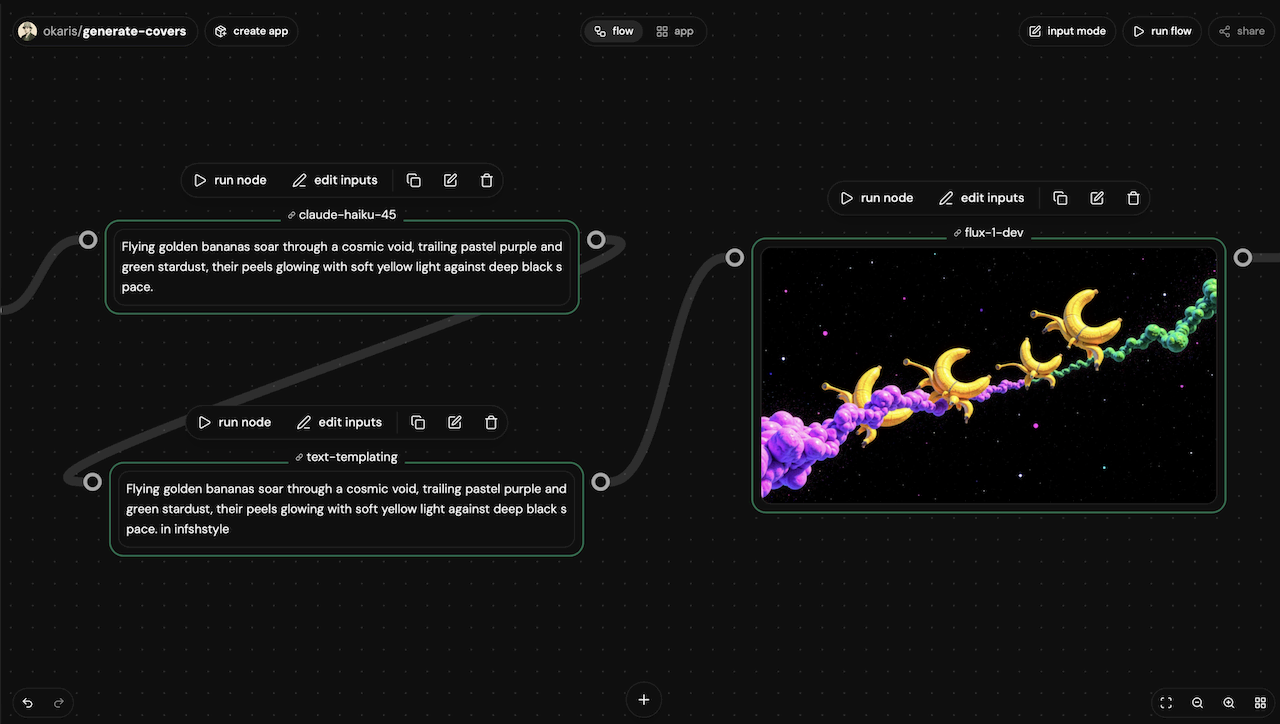
drag and drop to build the graph. map io to connect steps. deploy as an app.
we use cookies
we use cookies to ensure you get the best experience on our website. for more information on how we use cookies, please see our cookie policy.
by clicking "accept", you agree to our use of cookies.
learn more.